Support Vector Machines (SVM)
Beschreibung
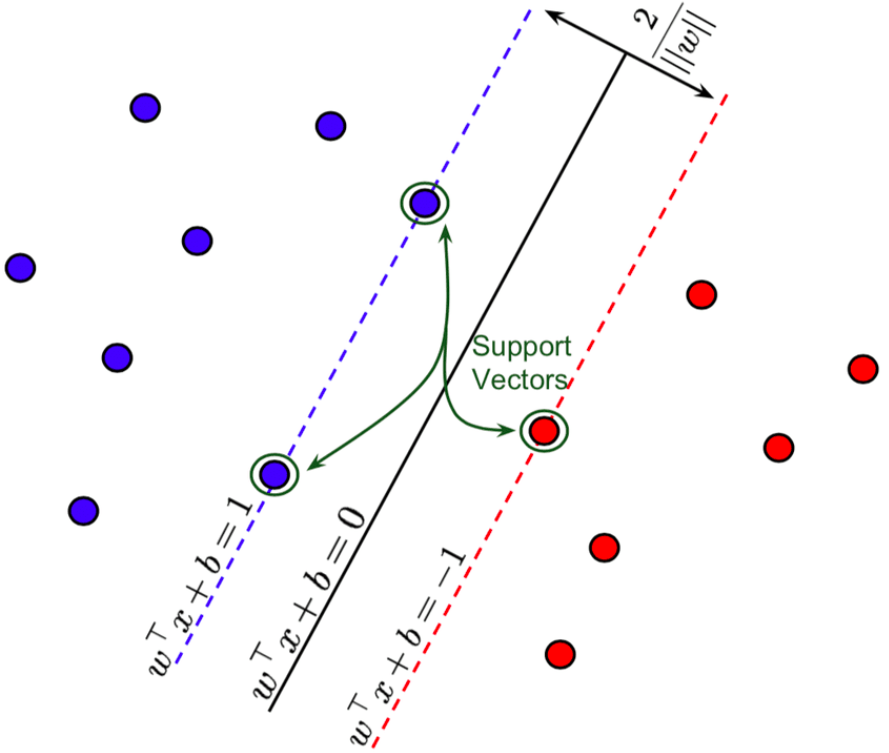
Bei Support Vector Machines will man die Klassen so voneinander trennen, dass der Abstand zwischen dein einzelnen Klassen maximal wird.
Die Trennlinie wird durch „Support Vektoren“ getrennt. Diese Trennline soll als Eigenschaft die größte Distanz zu den Vektoren besitzen.
Bei nichtlinearen Klassengrenzen können SVMs in einen Höherdimensionalen Raum transformiert werden um die Klassen dann zu unterschieden.
Theorie
SVM Modelle sind eine Repräsentation von Punkten im Raum. Jede Klasse wird dabei von einer maximalen Trennlinie getrennt. Neue Punkte werden „vorhersagend“ im selben Raum basierend auf der ermittelten Klasse gesetzt.
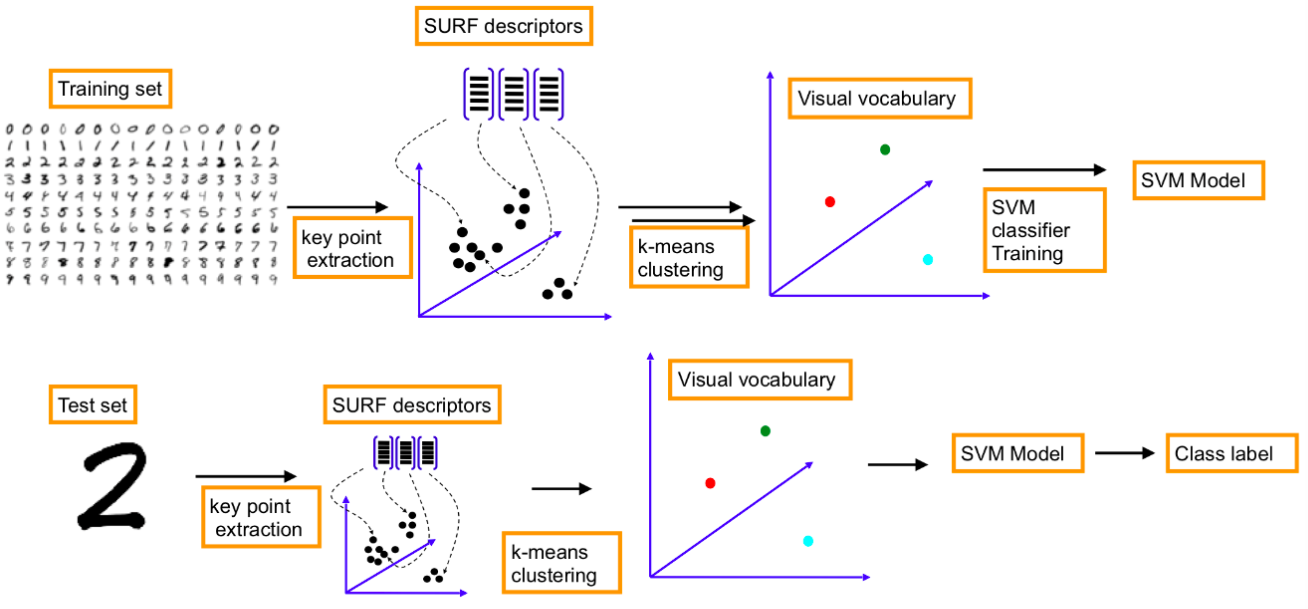
Umsetzung in Python
Vor- und Nachteile des Algorithmus
Vorteile:
- + Effektiv in Hochdimensionalen Räumen.
- + Auch für Probleme in welchen die Anzahl der Dimensionen größer ist als die Anzahl der Beispiele.
- + Speichereffizient weil ein Subset der Trainingspunkte erzeugt wird.
- + Sehr Flexibel, da verschiedene Kernelfunktionen für die Klassifikationsfunktion verwendet werden können.
Nachteile:
- - Wenn die Anzahl der Features viel Größer als die Anzahl der Beispiele ist passt der Algorithmus sich an das Problem an -> Overfitting.
- - SVMs geben keine direkte Wahrscheinlichkeit zurück, sondern müssen Kostenintensiv berechnet werden.