k-Nearest-Neighbors
Beschreibung
Hierbei handelt es sich um Klassifikationsverfahren. Der kNN-Algorithmus geht davon aus, dass ähnliche Dinge in unmittelbarer Nähe existieren. Mit anderen Worten, ähnliche Dinge sind nahe beieinander. Verwendet werden kann dieser Supervised-Learning Algorithmus sowohl für Klassifikations- als auch für Regressionsprobleme.
Theorie
Im Training werden die Input-Daten x(1), …, x(n) als Vektoren im Feature-Raum mit der dazugehörigen Label-Information gespeichert.
Bei der Klassifikation sei ein neuer Vektor x gegeben. Gesucht ist das dazugehörige Label t 0,1. Voraussetzung ist k > 0. Seien y(1), …, y(k) die Trainingsvektoren, für die der Euklidische Abstand zu x am geringsten ist. Wenn die Mehrheit dieser Vektoren das Label 0 besitzt, wird t = 0 gesetzt, andernfalls t = 1.
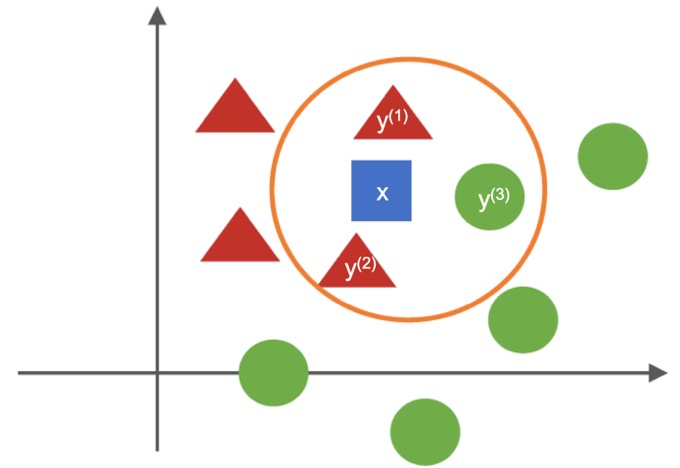
Beispielhaft erkennbar ist dies in obiger Abbildung. In diesem Fall soll das blaue Quadrat (x) einer Klasse zugeordnet werden. Die nächsten Nachbarn ( y(1), y(2), y(3) ) sind hierbei zwei rote Dreiecke und ein grüner Kreis, sprich k = 3. Da die Anzahl der roten Dreiecke überwiegt, wird das blaue Viereck ebenfalls der Klasse der roten Dreiecke zugeordnet.
Vor- und Nachteile des Algorithmus
Vorteile:
- + Der Algorithmus ist einfach und leicht zu implementieren.
- + Es ist nicht erforderlich, ein Modell zu erstellen, mehrere Parameter anzupassen oder zusätzliche Annahmen zu treffen.
- + Der Algorithmus ist vielseitig einsetzbar. Es kann für Klassifizierung, Regression und Suche verwendet werden.
Nachteile:
- - Der Algorithmus wird mit zunehmender Anzahl von Beispielen und/oder Prädiktoren/unabhängigen Variablen deutlich langsamer.
Quellen und weiterführende Links
Towards Data Science