Random Forest
Beschreibung
Random Forest wird zur Regression und Klassifizierung genutzt und besteht aus randomisierten Entscheidungsbäumen, sogenannten “Decision Trees”, bei dem jeder Baum mit einer Teilmenge der Daten erzeugt wird (Bagging). Die beste Aufteilung der Entscheidungsbäume wird nicht aus allen Merkmalen gesucht, sondern aus einer zufällig ausgewählten Untermenge. Random Forest gehört zur Klasse der “Supervised Learning”-Algorithmen, also Algorithmen mit einem überwachten Lernprozess.
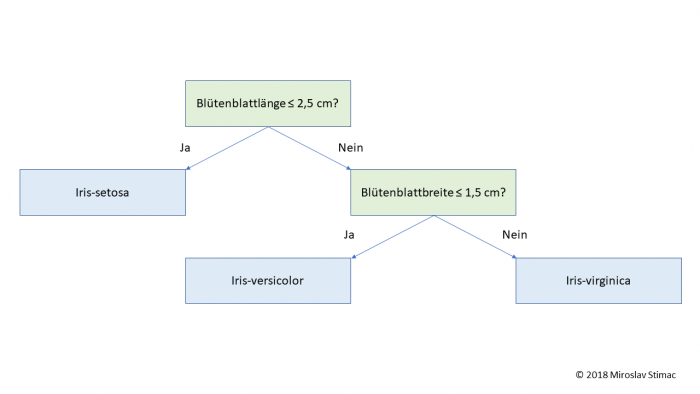
Theorie
Bagging ist die Kurzform von “Bootstrap Aggregating” und läuft in zwei Schritten ab:
1. Teile die Trainingsstichprobe in gleich große Teilmengen auf, z.B. durch willkürliches Ziehen von mehreren Elementen
2. Trainiere mit jeder Teilmenge S(i) jeweils einen Klassifikator
Vor- und Nachteile des Algorithmus
Vorteile:
- + Kleine Trainingsdatensätze erzielen bereits gute Vorhersagen.
- + Gute Generalisierung - Ergebnis ist weniger anfällig für Rauschen.
Nachteile:
- - Schlechte Interpretierbarkeit, da für die Auswertung der Daten ungeeignete Merkmalsräume entstehen können.
- - Bei einem kleinen Datensatz können die Ergebnisse sehr stark variieren.