CART (Classification and Regression Trees)
Beschreibung
Ein Beispiel für Decision Trees ist CART (Classification and Regression Trees). Ein Entscheidungsbaum ist eine weitgehend verwendete, nichtparametrische Modellierungstechnik für Regressions- und Klassifizierungsprobleme. Um Lösungen zu finden, trifft ein Entscheidungsbaum eine sequentielle, hierarchische Entscheidung über die Ergebnisvariable mit Hilfe der Prädiktor-Daten. Ein Beispiel ist in folgender Abbildung zu finden. Hierbei werden Songtitel (Trainingssatz) anhand von Merkmalen wie beispielsweise „Instrumentalness“, „Energy“ und „Danceability“ der Klasse 0 (orange; negativ bewertet) oder der Klasse 1 (blau; positiv bewertet; hier fehlt nach ‚class = ‘ die Zahl ‚1‘) zugeordnet.
Theorie
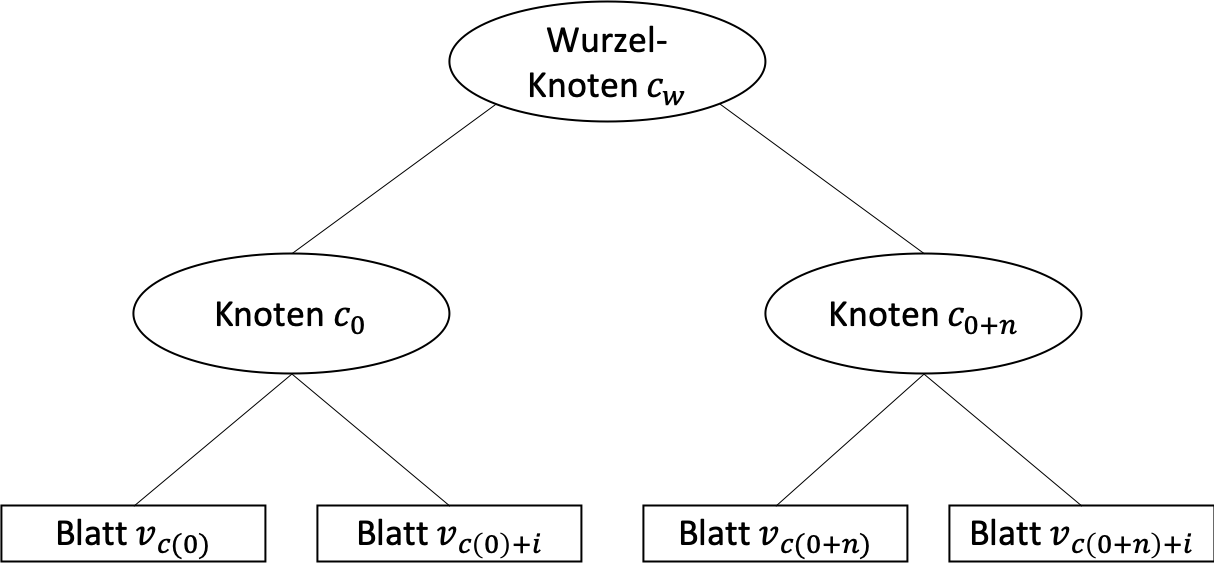
Bei einem Decision Tree spricht man häufiger von der Tiefe des Baumes. Die Tiefe ist gleichzusetzen mit der Anzahl der Ebenen (auszuschließen dem Wurzelknoten). Der obere Baum hat demnach eine Tiefe bzw. ein Level von 2.
Die Attribute werden nach Wichtigkeit sortiert, dabei stehen wichtige bzw. Aussagekräftige Attribute weiter oben im Baum. Als wichtig wird ein Attribut bezeichnet, wenn die Trefferquote einer Klassifizierung möglichst hoch ist.
Durch die Steigerung der Tiefe eines Baumes, steigt automatisch auch das Splitting der Daten. Während im oberen Beispiel die Daten auf maximal vier Blätter verteilt werden, sind es bei einem Level 3 Baum bereits acht mögliche Blätter. In unserem Fall liegt ein sogenannten binary splitting vor. Dies bedeutet, dass ein Knoten in zwei Wege gesplittet wird, um die Daten aufzuteilen (Beispiel, Regen: Ja, Nein). Beim multiway splitting dagegen, gibt es so viele Partitionen, wie es unterschiedliche Werte gibt (Beispiel, Wetter: sonnig, regnerisch, bewölkt). Praktisch werden aber meist binary splits verwendet.
Umsetzung in Python
Vor- und Nachteile des Algorithmus
Vorteile:
- + Entscheidungsbäume können von Natur aus eine Mehrklassenklassifizierung durchführen.
- + Sie bieten die meiste Modellinterpretierbarkeit, da es sich hierbei lediglich um eine Reihe von if-else-Bedingungen handelt.
- + Sie können sowohl numerische als auch kategorische Daten verarbeiten.
- + Nichtlineare Beziehungen zwischen Merkmalen haben keinen Einfluss auf die Performance der Entscheidungsbäume.
Nachteile:
- - Eine kleine Änderung im Datensatz kann die Baumstruktur instabil machen, was zu Abweichungen führen kann.
- - Wenn Klassen unausgewogen sind, werden undefit-trees erstellt -> Datensatz vor Anpassung an Entscheidungsbaum abgleichen.