Projektbeschreibung
Folgende Inhalte werden hier vermittelt!

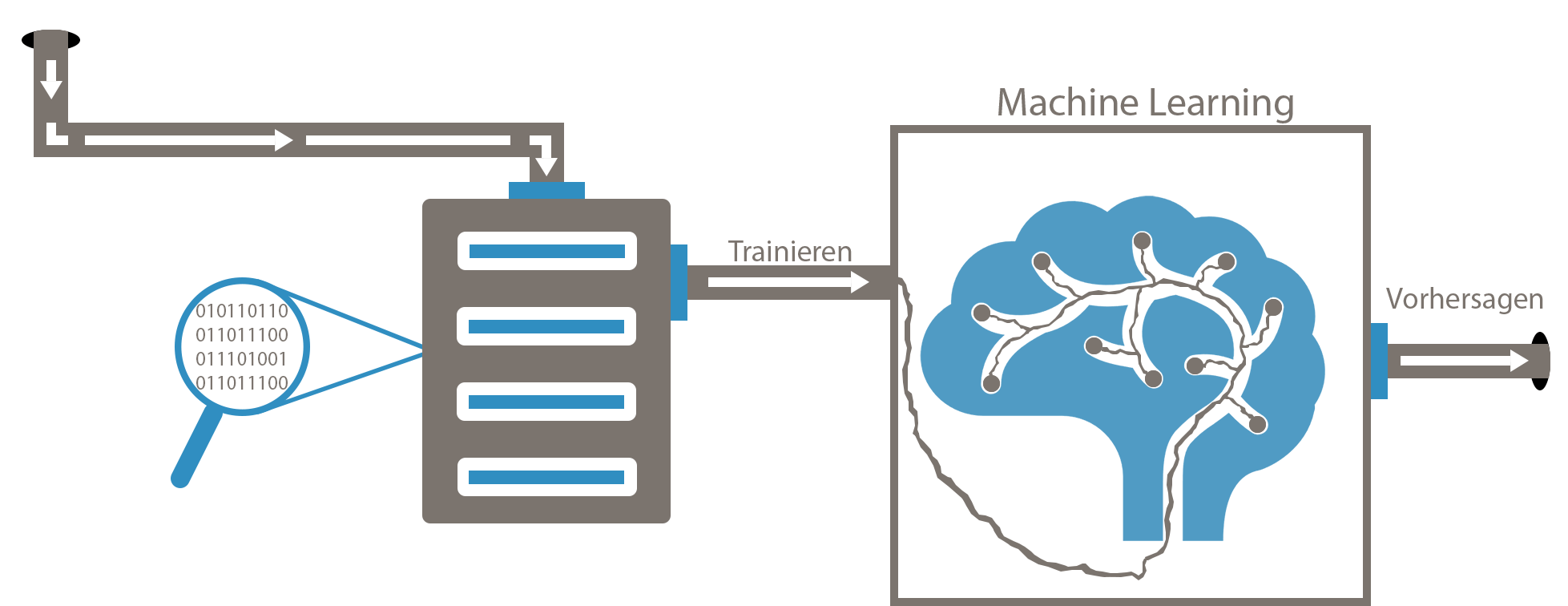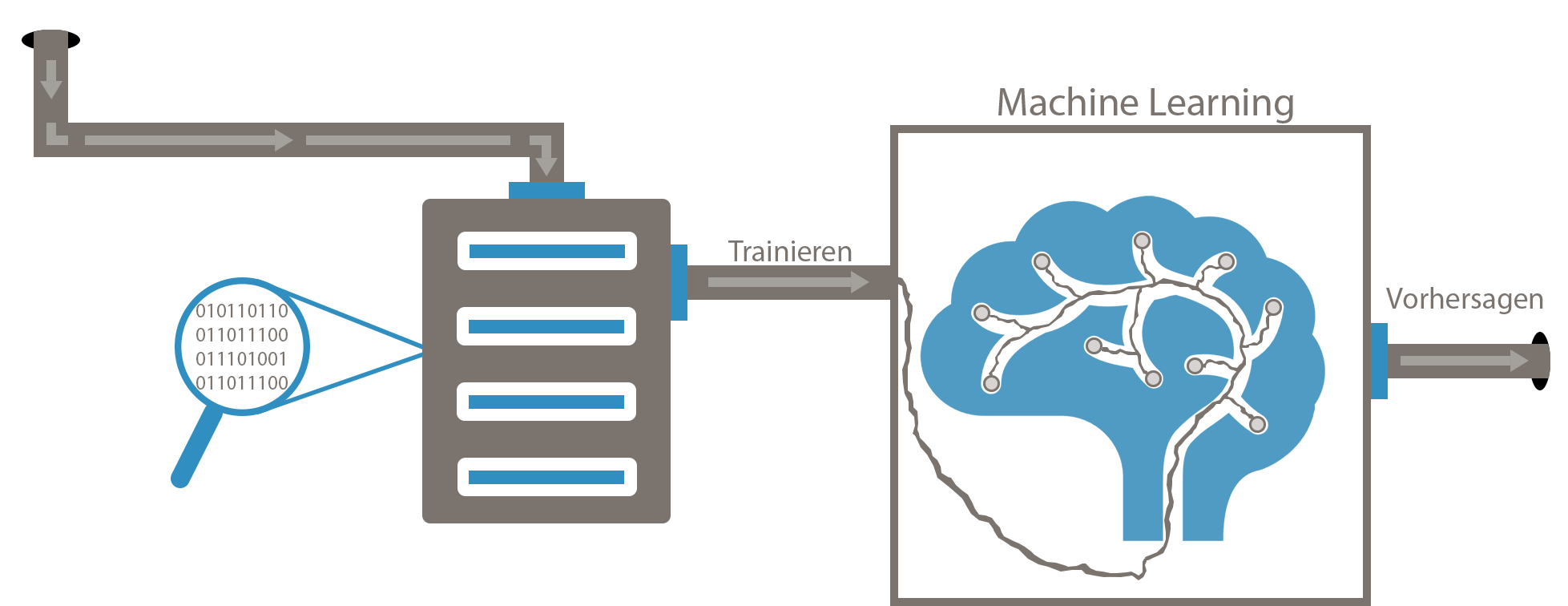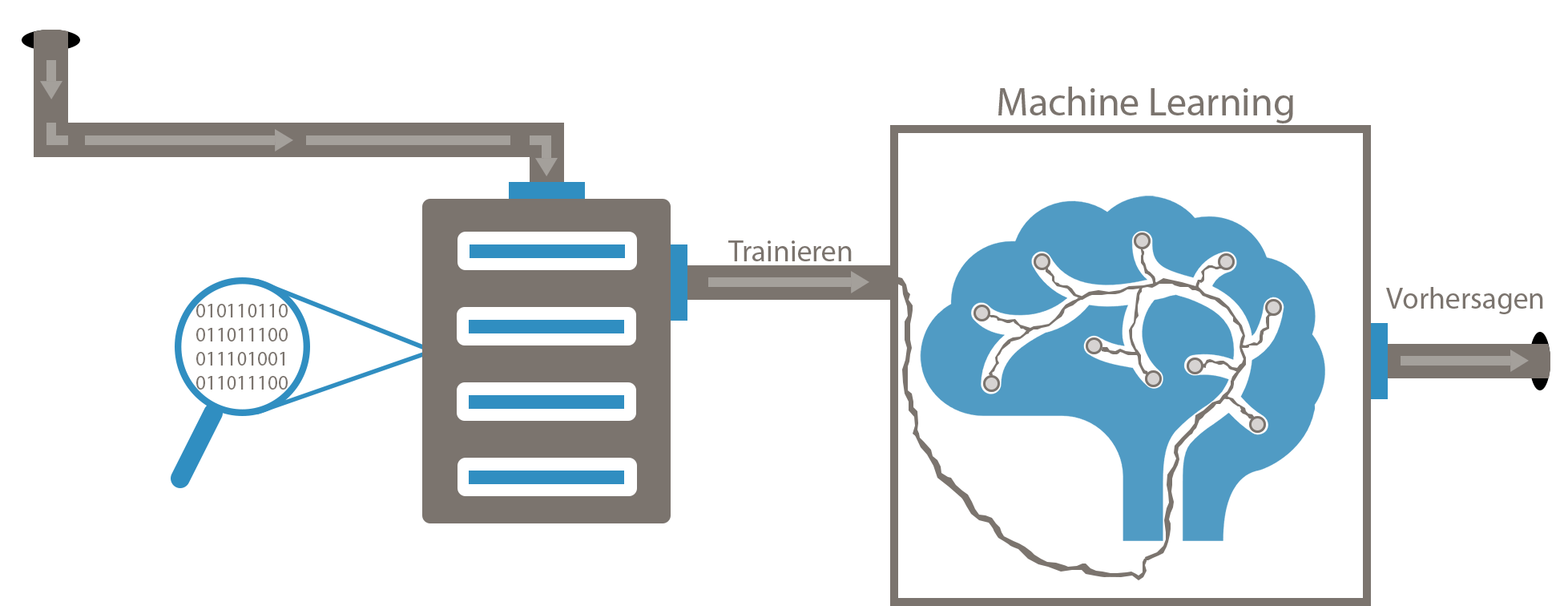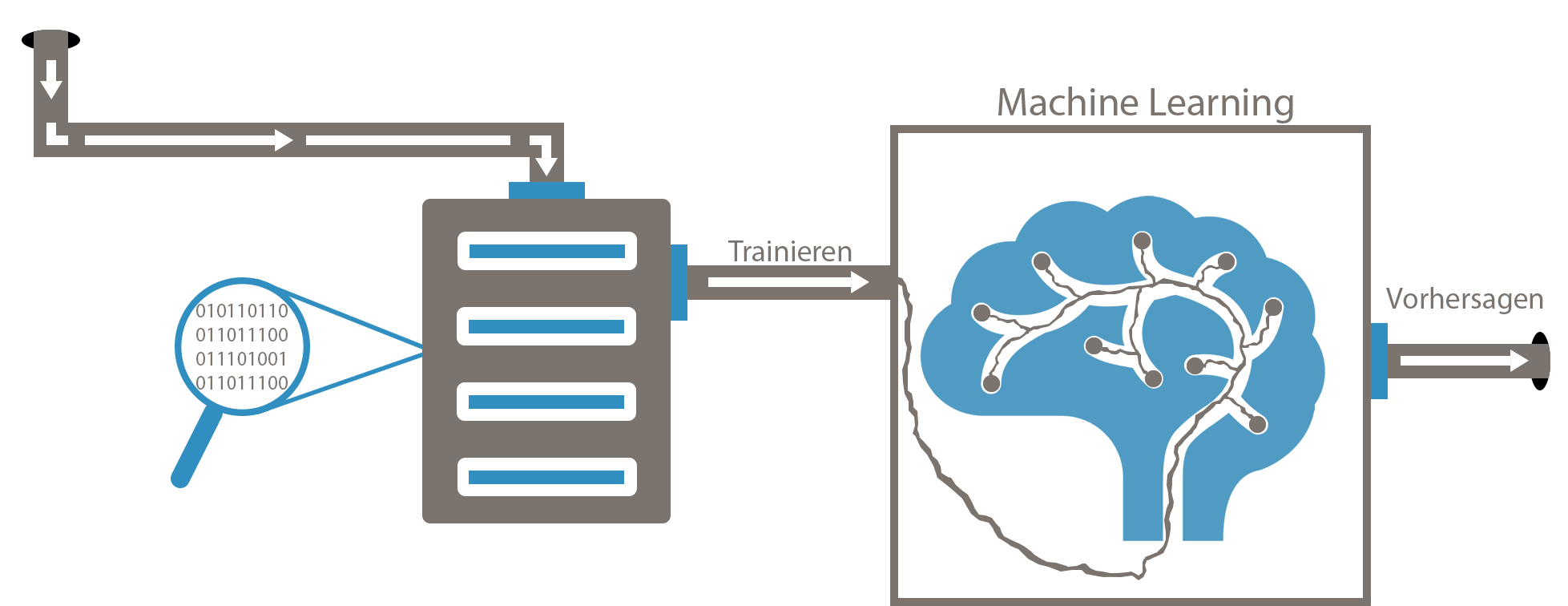
Machine Learning verstehen
Machine Learning, sowie künstliche Intelligenz im Allgemeinen, kann sehr komplex werden. Das Thema wird hierbei so verständlich wie möglich erklärt, dass auch Anfänger ohne Kenntnisse einen schnellen Einstieg in das Thema bekommen und zeitnah selbst eigene Versuche starten können.
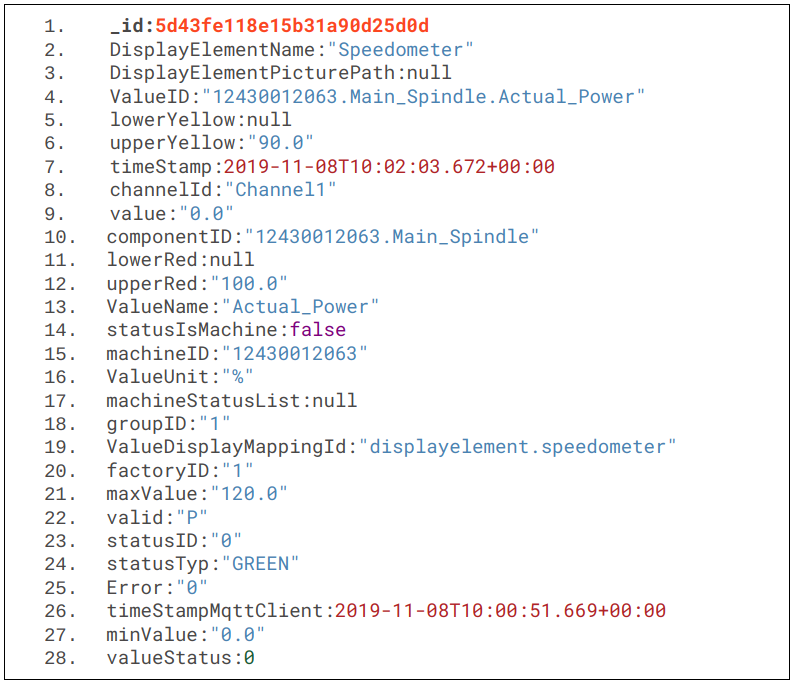
Machine Learning selbst ausprobieren
Hier wird nicht nur die Theorie vermittelt! Das wäre auf Dauer auch ziemlich langweilig. Es werden zahlreiche Codebeispiele und passende Datensätze bereitgestellt, sodass sofort eigene Versuche durchgeführt werden können.


Machine Learning anwenden
Die Theorie wurde verstanden und mit den Codebeispielen bereits erfolgreich eigene Versuche gestartet? Super! Dann kann das gelernte nun in der Praxis angewendet werden.
Über unser Projekt
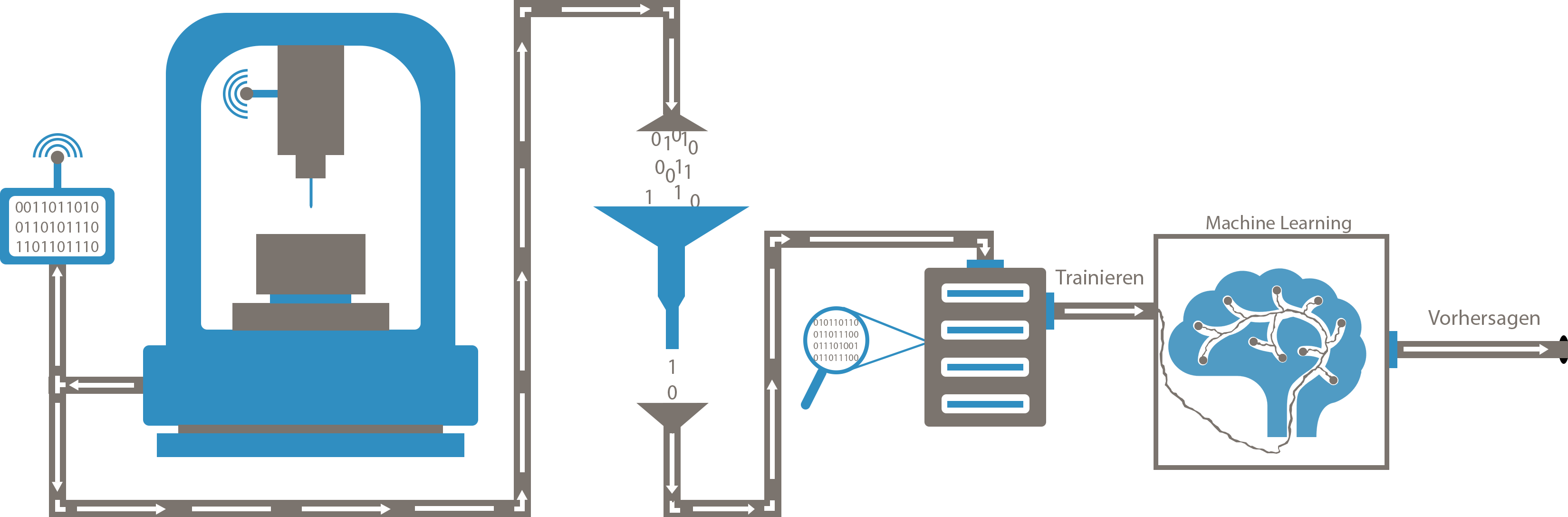
Um die Theorie des Studiums mit der Praxis des Arbeitsalltags zu verknüpfen, soll dieses Projekt dazu dienen, Einblicke und neue Erkenntnisse der digitalen Welt, insbesondere dem Bereich der Industrie 4.0 zu erlangen. Durch die Arbeitsumgebung des Digital Laboratory werden Grundlagen und Hilfsmittel zur Durchführung des Projekts bereitgestellt. Die vorhandene 5-Achs-Fräsmaschine der Firma DMG MORI liefert dafür den Use-Case und die dazu benötigte Grundlage für das Projekt.
Das Ziel des Projektes soll sein, mit Machine Learning eine Identifizierung der Einflussfaktoren während der Produktion zu erhalten, soll heißen welche Parameter einen starken, aktiven Einfluss auf den Fräsprozess haben und somit das Fräsergebnis beeinflussen. Diese Informationen können genutzt werden um später Machine Learning Modelle in Echtzeit für Fräsprozesse einsetzen zu können.
Zu den Grundlagen gehören neben Technologien wie TensorFlow und Python auch die zum Machine Learning gehörigen Lernmethoden Supervised-/Unsupervised-/Reinforcement-Learning und deren Algorithmen.
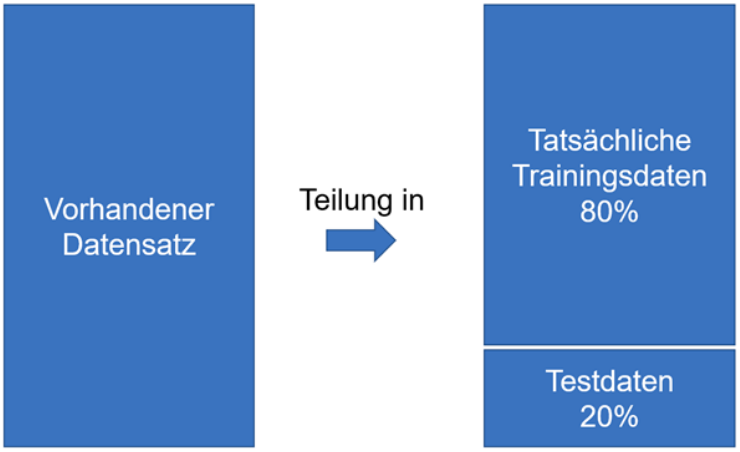
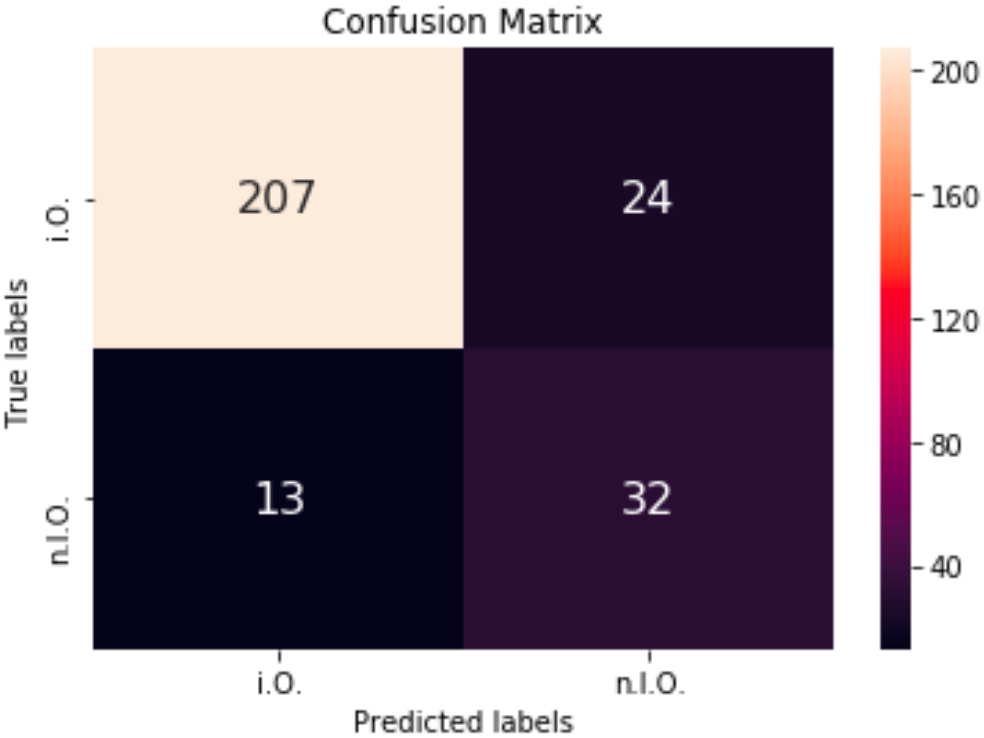
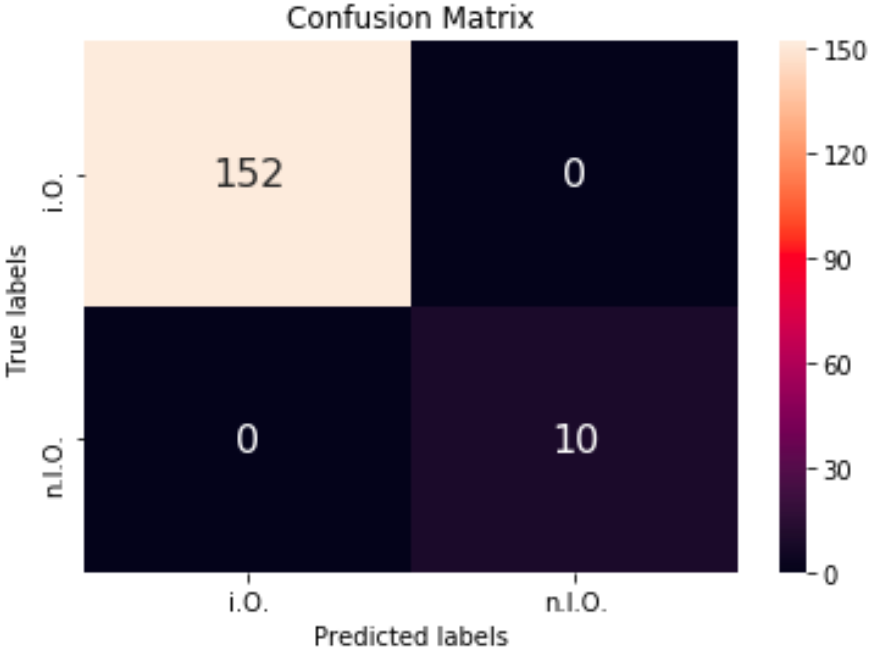
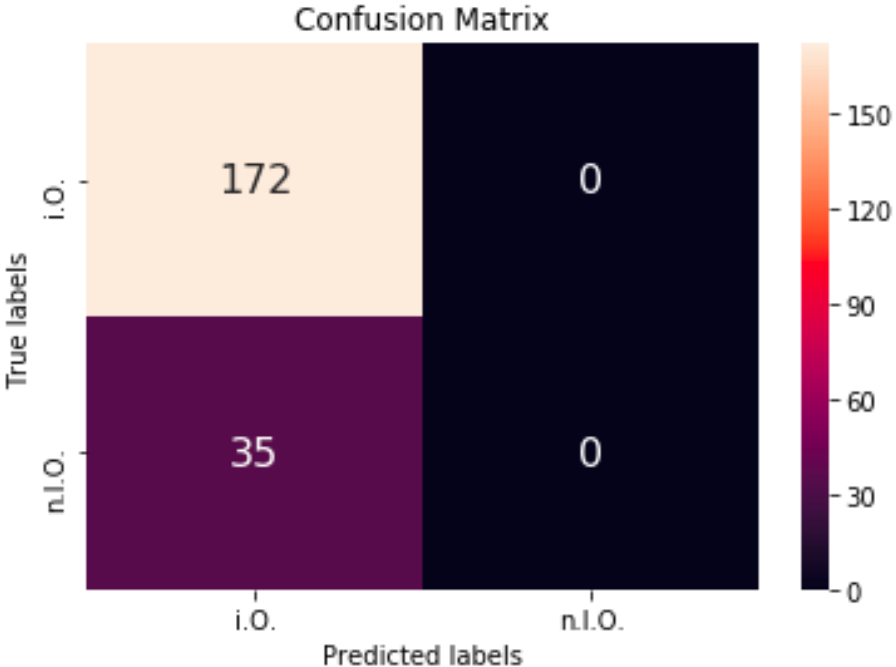
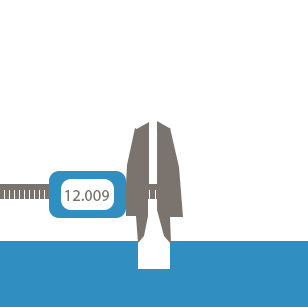
Sind die Grundlagen vermittelt worden, wird die Datengrundage geschaffen. Hier sollen mit der 5-Achs-Fräsmaschine und mehrere hundert Passungen nacheinander aus einem Stahlblock gefräst werden. Dazu soll die Toleranz jeder Passung mit dem Messmittel der Maschine ermittelt werden, um festzustellen, ab welchem Zeitpunkt bzw. welche Umstände dazu führen, dass die gefrästen Löcher außerhalb des Toleranzbereichs liegen. Die Beurteilung erfolgt später über die Kennzeichnung (Labeling) der Löcher in die Kategorien IO/NIO.
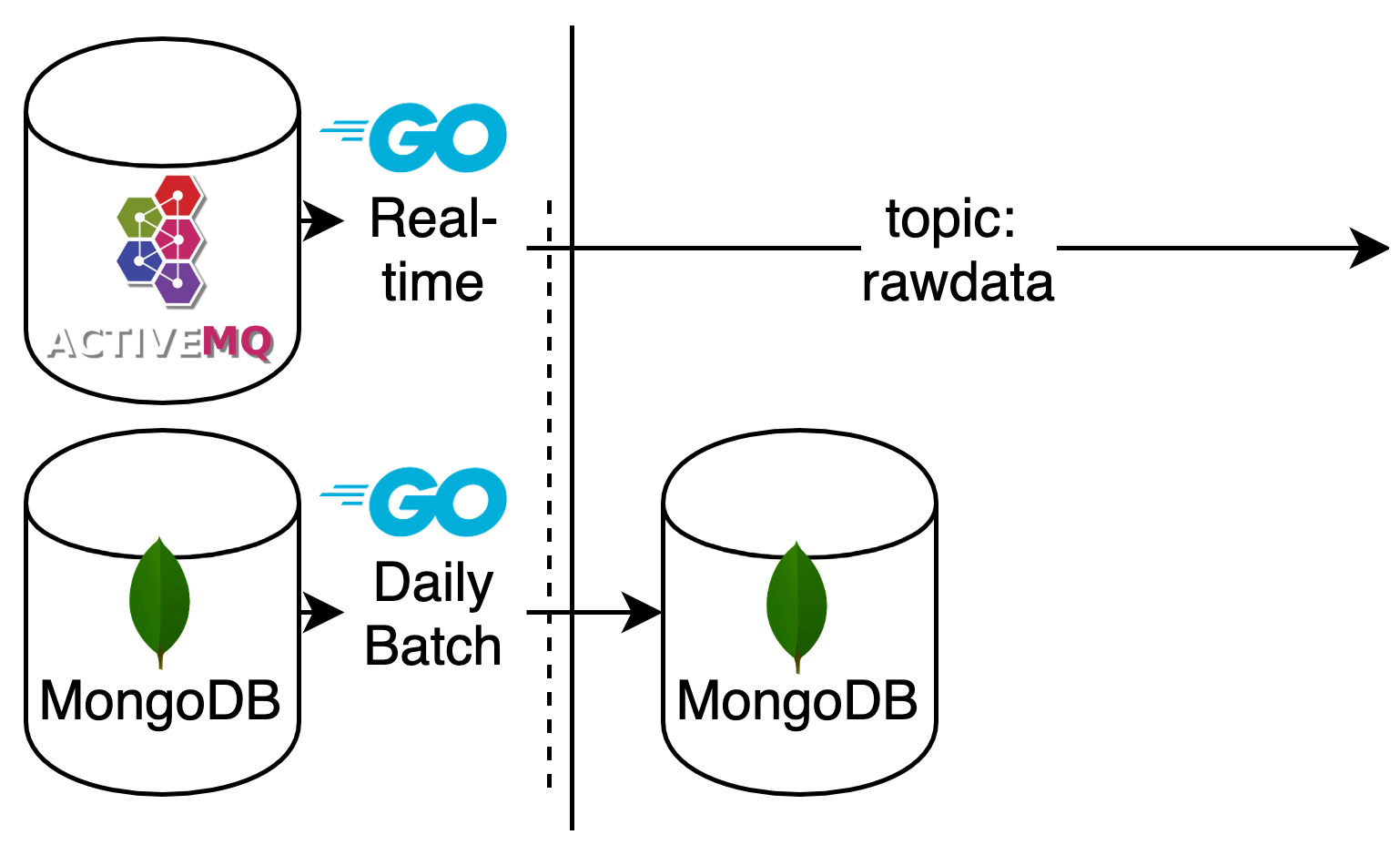
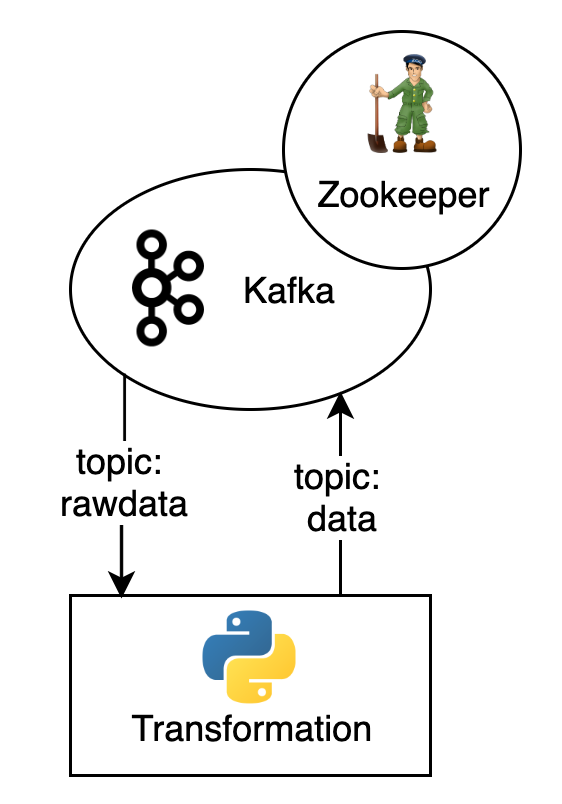
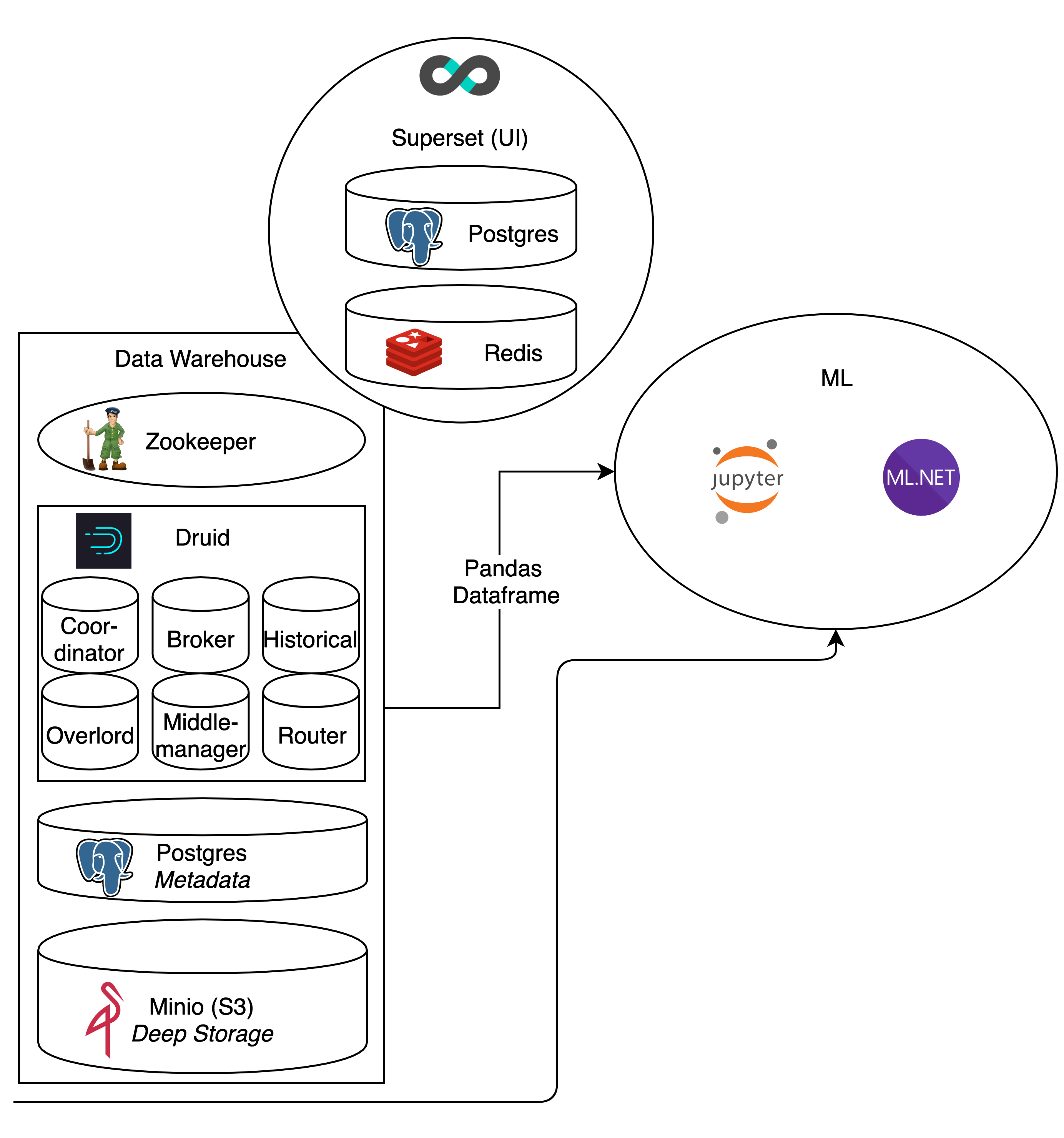
Die gewonnen Daten werden in einer Datenbank gespeichert und durch ETL-Prozesse so bearbeitet, dass diese anschließend von Machine Learning Algorithmen genutzt werden können.